Préambule
Cela fait quelques mois que j’observe de loin l’évolution de ce que tout le monde appelle l’IA, dans ce billet, je parlerai plus spécifiquement d’IA générative.
Mes objectifs, depuis le début de ma démarche, sont multiples :
- Essayer de comprendre ce que c’est
- Comment l’utiliser
- Essayer de me faire une idée des conséquences sur mes domaines d’expertise
J’en étais jusque-là resté au perceptron et aux systèmes experts. Oui, ça date !
Introduction
Je ne souhaite pas, ici, faire le tour de toutes les incidences possibles de l’IA sur la sécurité informatique, SSI, Infosec, « cyber ». Je ne souhaite pas évaluer comment l’IA générative peut améliorer les mails d’hameçonnage. Ni comment contourner les limitations des LLM pour créer de nouveaux malware.
Je souhaite dans ce billet creuser une architecture particulière que je trouve pertinente, les RAG (Retrieval-Augmented Generation), ou en français : Génération Augmentée par Recherche.
C’est une architecture d’IA qui combine :
- Un moteur de recherche (pour retrouver des informations pertinentes)
- Un modèle de langage (LLM) (pour rédiger la réponse finale)
L’idée est simple :
Avant que l’IA réponde, elle va chercher dans une base de connaissances (notre propre corpus de données : documents office, PDF, sites/bases internes, etc.) les passages utiles, puis les utilise comme contexte pour générer une réponse plus fiable/adaptée.
Un LLM « classique » (ChatGPT, Llama, etc.) :
- Peut « halluciner » (fournir des réponses fantaisistes)
- N’a pas accès à vos documents privés
- Ne connais que ce sur quoi il a été entraîné
Un RAG tente de corriger cela.
outefois, l’intérêt principal d’un RAG, vient du fait qu’il n’est pas nécessaire de créer un nouveau model et de l’entraîner sur vos propres données pour générer du contenu correspondant à vos requêtes. Ceci serait un travail complexe et très couteux. Un RAG utilise un modèle existant déjà entrainé mais en lui ajoutant dans le contexte du prompt, les fragments de texte (chunks) les plus pertinents de votre corpus d’information.
Si un RAG travaille à partir de votre corpus d’information (vos documents, qui peuvent être sensibles), il est indispensable de comprendre comment cela fonctionne ou au moins quels sont les flux et les traitements de données mis en œuvre.
Pour ce faire, rien de tel que de concevoir et de fabriquer un prototype soi- même. Heureusement presque tout est déjà disponible !
Description de notre prototype
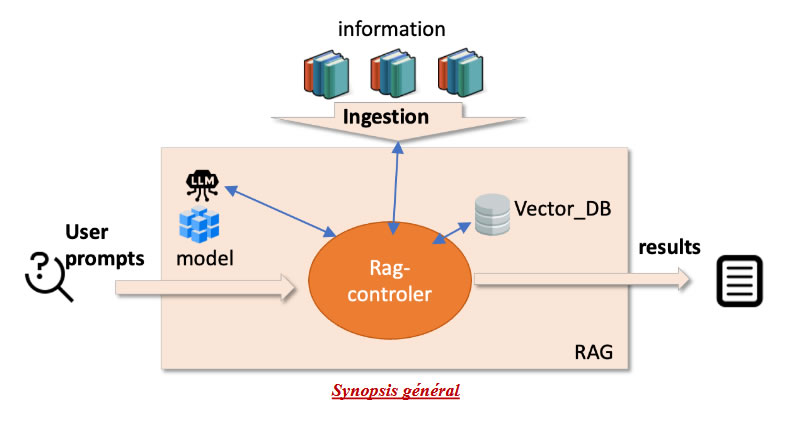
Les Principales fonctionnalités de notre RAG sont très similaires à ce qui existe un peu partout.
- Préparation du Rag :Avant d’être utilisé un RAG doit être configurer/préparé pour être le plus pertinent selon nos propres informations. Je vais appeler cette phase l’ingestion, cette phase est chargée de préparer nos informations et de les stocker en différents petits fragments de texte (chunks). Ces chunks seront vectorisés et stockés localement. Cette phase est à refaire si les informations en entrée sont modifiées, mais conserver un hash des documents indexés, permet de ne réindexer que ce qui a changé.
Cette ingestion/indexation, comporte plusieurs sous étapes :
- Extraction du texte
Les LLM ne travaillent que sur du texte (Large Language Model)

- Fragmentation (Chunking)
Les LLM (comme Llama ou GPT) ont une limite de contexte :ils ne peuvent lire qu’un certain nombre de tokens (pour simplifier disons de mots). Un rapport de 200 pages ne peut pas être vectorisé ni envoyé en entier. On le découpe donc en petites portions/fragments : les chunks.

- Vectorisation (embedding)
Comme les contextes ont des tailles limitées, il est nécessaire de pouvoir sélectionner les chunks les plus pertinents pour un prompt. Les chunks sont sélectionnés selon la sémantique qu’ils contiennent. Pour cela il faut calculer le vecteur sémantique de chaque chunk. Nous réalisons ceci avec un modèle de vectorisation (embedding model), comme par exemple :
o nomic-embed-text,
o mxbai-embed-large,
o snowflake-arctic-embed,
o etc.
Nous utilisons nomic-embed-text via ollama pour réaliser la vectorisation de chaque chunk de notre RAG. Sans vectorisation, le RAG n’a aucun moyen de comparer la similarité sémantique de 2 chunks (ou d’un chunk et du vecteur du prompt).

Au passage un vecteur ici est juste une liste de valeurs réelles. Pour le vérifier manuellement voici une vectorisation réalisée avec curl :
curl -n -s http://ollama:11434/api/embed -d ‘{
« model »: « nomic-embed-text »,
« input »: [« CSM Rulez »],
« keep_alive »: « 10m »
}’|jq
Résultat:
{
« model »: « nomic-embed-text »,
« embeddings »: [
[
0.047080193,
-0.011332598,
-0.16450249,
0.052621804,
0.0282522,
-0.019088987,
0.06287004,
0.012715586,
-0.027301848,
-0.0103261415,
-0.036762334,
… Vecteur de 768 éléments au total …
0.030251738,
0.035093635,
-0.024630867,
-0.03827852,
-0.03900068,
-0.033920094
]
],
« total_duration »: 58146858,
« load_duration »: 17569727,
« prompt_eval_count »: 4
}

- Stockage des fragments (avec leur origine source et leur vecteur) Dans notre RAG nous devons conserver tous les chunks, avec leur origine et surtout leur vecteur. Pour cela il est possible d’utiliser différents produits comme SQLite-VSS,Chroma,Qdrant ou Milvus. Pour notre POC écrit en go, nous utilisons simplement SQLite (suffisant jusqu’à 1M de chunks).
2. Utilisation du Rag : Une fois prêt, notre RAG peut être utilisé, c’est à dire générer du contenu répondant à des requêtes (prompts). En réalité le prompt écrit par l’utilisateur, est contextualisé avec les meilleurs chunks pour le prompt saisi.
Exemple :
Context:
<Texte du chunk 1…>
<Texte du chunk 2…>
<Texte du chunk 3…>
Question:
Prompt saisi par l’utilisateur
a) Construction de la requête pour le LLM (prompt + meilleurs chunks)
i) Saisie du prompt de l’utilisateur et vectorisation de ce prompt Dès que l’utilisateur a saisi un prompt. Le Rag vectorise ce prompt avec la même méthode que pour vectoriser un chunk. (appel de ollama
/api/embed en sélectionnant le modèle nomic-embed-text.
ii) Je ne traite pas ici les phases optionnelles d’optimisation du prompt (reranking, etc.)
iii) Sélection des meilleurs chunks dans la base de données (vectorielle) interne du Rag. Pour ajouter du contexte au prompt il faut sélectionner entre 3 et 8 chunks, les plus proches sémantiquement du prompt. Il faut donc un moyen mathématique pour mesurer une proximité sémantique entre 2 chunks (ou un chunk et un prompt). C’est là que les vecteurs sémantiques calculés avec un modèle de vectorisation sont essentiels. Dans notre rag ils ne servent qu’à ça.
Illustration basique :
Chunk1 : « la voiture est très rapide et puissante » => V1
Chunk2 : « un véhicule puissant avec une grande vitesse » =>V2
Les contenus des chunks sont différent, mais les vecteurs sémantiques V1 et V2 pointerons dans une direction similaire. Ainsi il est plus simple algorithmiquement de comparer 2 vecteurs que 2 textes. Une méthode simple s’appelle la similatité cosinus (cosine similarity) : La similarité cosinus mesure à quel point deux vecteurs sont orientés dans la même direction, indépendamment de leur longueur. C’est cette méthode que nous utilisons dans notre POC pour trouver dans notre base de vecteurs, les chunks qui sont les plus proches du prompt :
func cosine(a, b []float64) float64 {
var dot, na, nb float64
for i := range a { dot += a[i]*b[i]; na += a[i]*a[i]; nb +=
b[i]*b[i] }
if na == 0 || nb == 0 { return 0 }
return dot / (math.Sqrt(na) * math.Sqrt(nb))
}
iv) Construction de la requête :
La requête est un POST http sur l’API d’un moteur de LLM sous la forme :
POST /api/chat
Context:
<Texte du chunk 1…>
<Texte du chunk 2…>
<Texte du chunk 3…>
Question:
Prompt saisi par l’utilisateur
Context:
<Texte du chunk 1…>
<Texte du chunk 2…>
<Texte du chunk 3…>
Question:
Prompt saisi par l’utilisateur
b) Génération du résultat
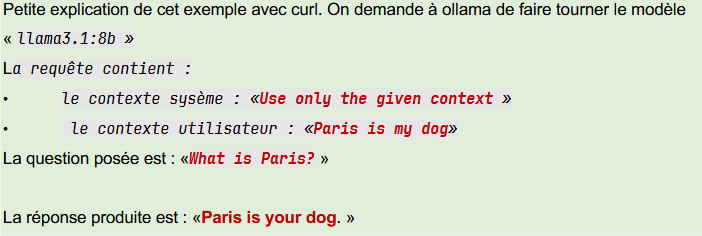
La génération du résultat consiste alors à simplement envoyer notre requête avec ses contextes (système et utilisateur) à un moteur de LLM en lui indiquant quel modèle utiliser. Nous utilisons : llama3.1:8b

Exemple de requête manuelle avec curl
Fichier chat.sh :
curl -s -N http://ollama:11434/api/chat -d ‘{
« model »: « llama3.1:8b »,
« messages »: [
{« role »: »system », »content »: »Use only the given context. »},
{« role »: »user », »content »: »Context: Paris is my dog\n\n\n\nQuestion: What is Paris? »}
],
« stream »: true,
« options »: { « temperature »: 0.1, « num_ctx »: 8192 },
« keep_alive »: « 10m »
}’
Remarque : Il est aussi possible d’utiliser « /api/generate » !
résultat :
# sans jq:
⇒ sh chat.sh
{« model »: »llama3.1:8b », »created_at »: »2025-11-
11T18:50:14.267743101Z », »message »:{« role »: »assistant », »content »: »Paris »}, »done »:false}
{« model »: »llama3.1:8b », »created_at »: »2025-11-
11T18:50:14.529326552Z », »message »:{« role »: »assistant », »content »: » is »}, »done »:false}
{« model »: »llama3.1:8b », »created_at »: »2025-11-
11T18:50:14.794494852Z », »message »:{« role »: »assistant », »content »: » your »}, »done »:false}
{« model »: »llama3.1:8b », »created_at »: »2025-11-
11T18:50:15.057134844Z », »message »:{« role »: »assistant », »content »: » dog »}, »done »:false}
{« model »: »llama3.1:8b », »created_at »: »2025-11-
11T18:50:15.31976175Z », »message »:{« role »: »assistant », »content »: ». »}, »done »:false}
{« model »: »llama3.1:8b », »created_at »: »2025-11-
11T18:50:15.588448383Z », »message »:{« role »: »assistant », »content »: » »}, »done_reason »: »stop », »done
« :true, »total_duration »:6986893458, »load_duration »:83527902, »prompt_eval_count »:34, »prompt_eva
l_duration »:5579874574, »eval_count »:6, »eval_duration »:1322626967}
# avec jq :
⇒ sh chat.sh|jq -r ‘.message.content’
Paris
is
your
dog
.